

Previsioni di serie temporali con Prophet e Metaflow
Nell’ambito di un progetto di anomaly detection, ho recentemente potuto utilizzare due prodotti open source molto interessanti: Prophet, rilasciato dal Core Data Science team di Facebook e Metaflow, un ottimo framework di Netflix. Ho utilizzato Prophet, in un flusso Metaflow, per realizzare dei modelli previsionali di serie storiche. Ho deciso di scrivere questo post per condividere la mia esperienza con questi due prodotti, realizzando un piccolo progetto di machine learning. [photo by Djim Loic on Unsplash]
Un piccolo progetto
Riuscire a prevedere il futuro andamento di una serie storica è utilissimo in molte applicazioni, dal mondo della finanza all’impresa. Si cerca, per esempio, di prevedere la direzione del mercato azionario o il corretto approvvigionamento di risorse. Questo post non si pone obiettivi così ambiziosi, ma vuole solo esplorare le possibilità offerte da Prophet realizzando un modello previsionale che determini il futuro andamento delle temperature giornaliere. Per effettuare il training del modello, ho utilizzato un dataset che raccoglie le temperature minime giornaliere su 10 anni (1981-1990) nella città di Melbourne, in Australia. La fonte dei dati è Australian Bureau of Meteorology.
L’intero codice sorgente del progetto è disponibile in questo repository git.
Esplorazione dei dati
Analizziamo il nostro dataset con un semplice notebook. Utilizziamo Python e Pandas per caricare il file CSV.
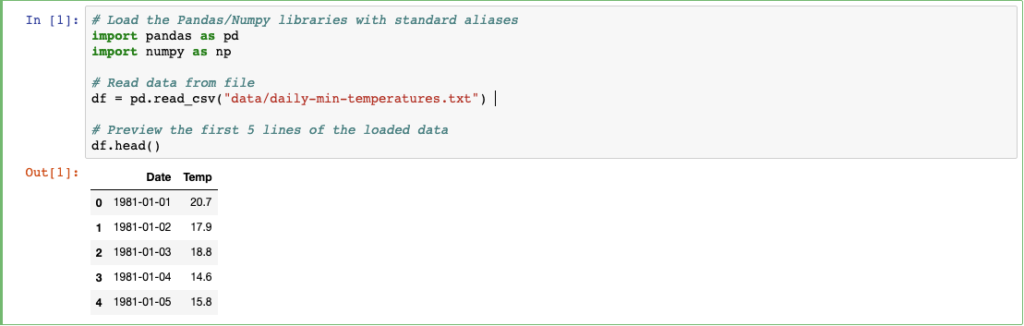
Il file si presenta con due semplici colonne, indicanti rispettivamente data della misurazione e temperatura. Proviamo a visualizzare i dati e la relativa distribuzione.
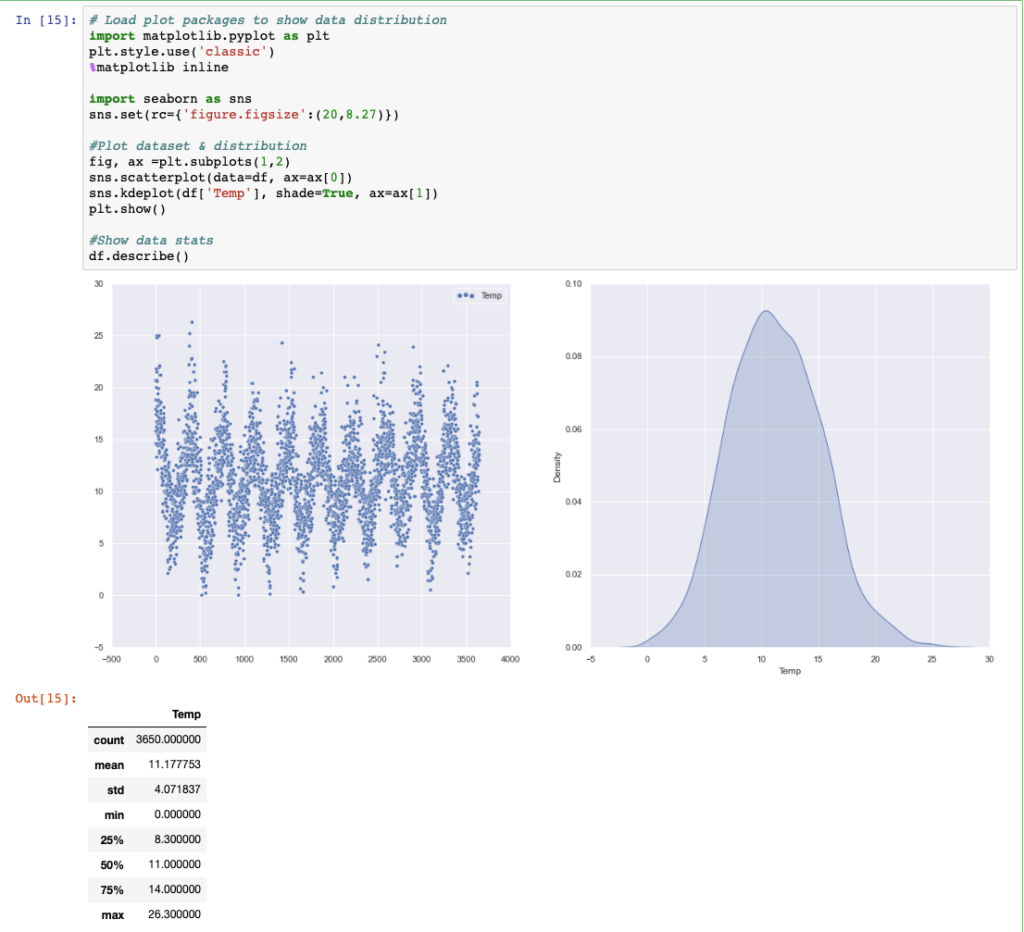
Ottimo: il dataset si presenta bilanciato e la periodicità dell’andamento della temperatura nell’arco degli anni è ben evidente. Possiamo provare ad utilizzare Prophet.
Facebook Prophet
Vediamo come sia semplice, con Prophet, effettuare delle previsioni sull’andamento di serie temporali.
Per prima cosa dovremo ovviamente preoccuparci di installare il package Python.
pip install fbprophetProphet accetta un dataframe Pandas come base dati su cui effettuare il training. Il dataframe deve avere due colonne, DS – cioè la data della misurazione e Y – il valore della misurazione. Occupiamoci quindi di sistemare le nostre feature prima di sottoporle al metodo di fit del modello.
# Rename columns to meet Prophet input dataframe standards
df.rename(columns={'Date':'ds','Temp':'y'},inplace=True)
# Convert Date column to datetime64 dtype
df['ds']= pd.to_datetime(df['ds'], infer_datetime_format=True)Siamo ora pronti per effettuare il training del modello con il metodo fit.
m = Prophet()
m.fit(df)Tutto qui? Esattamente. Prophet si vanta di essere una procedura automatica che consente molto rapidamente di effettuare previsioni su dati temporali, individuando stagionalità, trend ed eliminando valori anomali. L’operazione di fitting è anche molto rapida.
Proviamo ora a prevedere il futuro andamento delle nostre temperature per l’anno successivo. Questo risultato si ottiene sottoponendo a Prophet un dataframe dove la colonna DS indica le date di interesse.
E’ possibile sfruttare dei metodi già presenti nel framework per estendere, per esempio, il dataframe iniziale del numero di giorni desiderato.
# Prepare dataframe for prediction (add 365 days)
future = m.make_future_dataframe(periods=365)
# Predict future values
forecast = m.predict(future)Fatto! Il dataframe riporta ora le previsioni (yhat) della nostra serie temporale per il periodo richiesto.
Il framework di Facebook ci permette anche di disegnare rapidamente la nostra serie temporale e il futuro andamento della stessa comprensivo del range di confidenza. Ancora più interessante è la possibilità di rappresentare su figure differenti, le componenti (trend e stagionalità) della nostra serie.
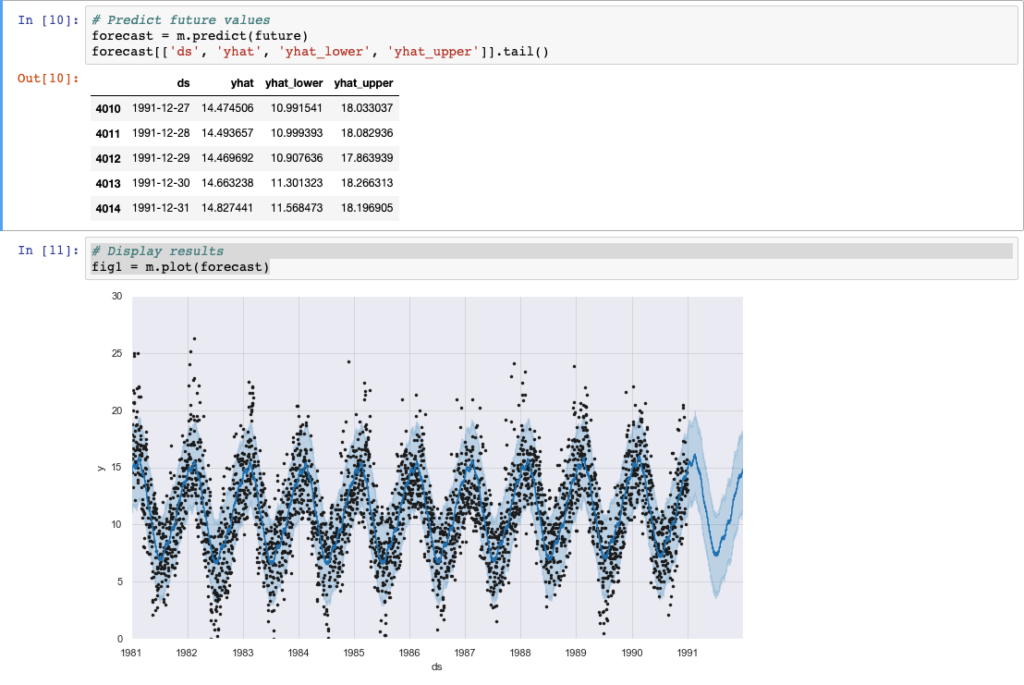
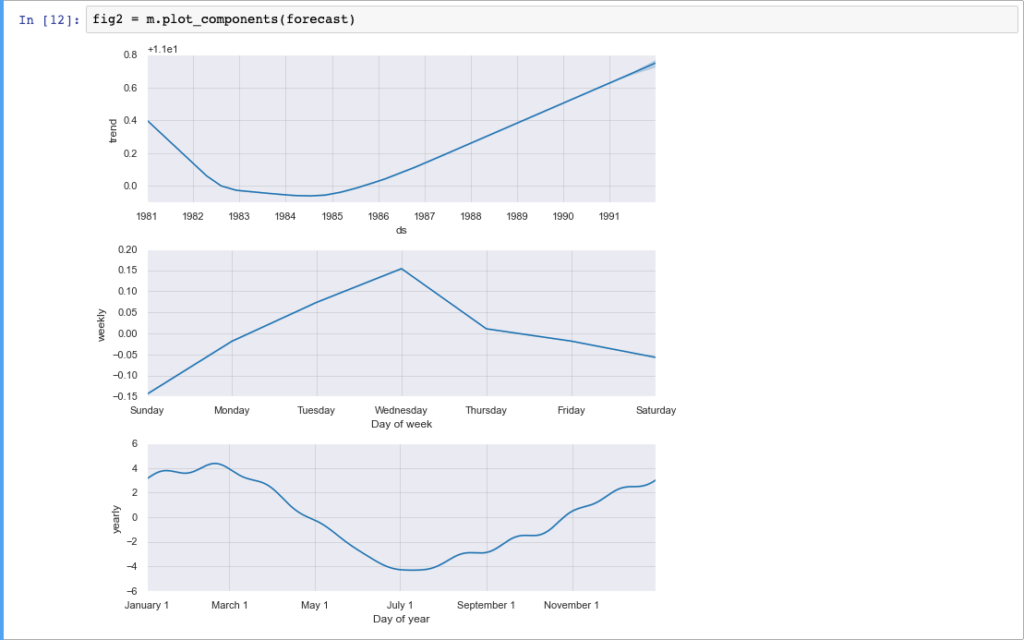
Davvero uno strumento molto potente e semplice da utilizzare. Non cadiamo però nell’errore di considerarlo sin troppo semplice: quanto abbiamo appena visto è di fatto un “quick start” per coglierne le possibilità. Per situazioni più complesse o quando si vuole ottenere risultati migliori, Prophet consente di impostare diverse opzioni, quali:
- Modello lineare / logistico di crescita
- Saturazione al minimo
- Flessibilità del trend
- Changepoints (automatici e custom)
- Festività ed eventi speciali (automatiche e custom)
- Stagionalità (custom, additive e moltiplicative)
- Parametri di incertezza (del trend e della stagionalità)
Esistono quindi diversi parametri su cui possiamo agire per adattare al meglio il nostro modello ai dati che stiamo analizzando. L’ottima documentazione ci aiuta a comprenderne l’utilizzo. Noi ci limiteremo, per questo progetto, a sperimentare valori diversi per alcuni iperparametri, in modo da migliorare le nostre predizioni. Il processo non sarà svolto in un altro notebook: al contrario, validato l’approccio, preferiamo utilizzare un framework che ci guidi nel processo di realizzazione e gestione del nostro progetto di data science. E’ arrivato il momento di utilizzare Metaflow!
Metaflow
Metaflow ci aiuta a progettare il flusso di lavoro, suddividendolo in step. E’ possibile eseguire l’elaborazione su larga scala, grazie all’integrazione con il cloud AWS. Si occupa automaticamente di versionare i dati ed i nostri esperimenti (run). Come per Prophet, anche Metaflow è disponibile sia per Python che per R.
E’ sempre una buona idea utilizzare Metaflow? In generale si, se nell’ambito del nostro progetto avremo bisogno di elaborare i dati su larga scala (e non esclusivamente sul nostro laptop) o condividere il progetto con altre persone.
Procediamo con l’installazione:
pip install metaflowAppena installato, Metaflow è configurato per l’esecuzione locale dei flow. Vedremo in seguito come configurare l’esecuzione in cloud.
Ma cos’è un flow? Un flow è una serie di step che eseguono l’elaborazione dei dati nell’ambito del nostro progetto. Nel caso più semplice, gli step sono lineari cioè eseguiti uno di seguito all’altro.
Metaflow consente inoltre di definire step la cui esecuzione avvenga in parallelo, funzionalità necessaria per garantire la scalabilità in cloud.
In ogni flow, ciascuno step “richiama” il successivo. Nel caso di task paralleli, uno step “padre” determina poi l’esecuzione di step “figli” in più branch. Ogni branch può essere composto da più step e a sua volta può suddividersi ulteriormente. I branch possono implementare elaborazioni differenti oppure possono essere identici, ma destinati ad elaborare in parallelo lotti di dati diversi. Al termine dell’esecuzione dei task in parallelo, questi vengono sempre consolidati in uno step di “join”, il cui scopo è raccogliere i risultati (artefatti) dell’esecuzione.

Prendiamo in prestito questa immagine direttamente dalla documentazione di Metaflow: lo step “start” determina la creazione di più task di tipo “a” in parallelo. Al termine dell’esecuzione, questi vengono consolidati nello step “join”, seguito poi dall’ultimo step del flow “end”.
ProphetFlow
Proviamo ora a “convertire” il nostro notebook, effettuandone il porting su Metaflow.
Ogni flow è uno script che può essere eseguito specificando dei parametri e dei data file di input. Il decorator @step definisce i passaggi del nostro flow, a partire da “start” che si occupa di caricare i dati dal file CSV in un dataframe pandas. Nello step successivo ci occupiamo di effettuare il training del modello Prophet, al quale seguirà lo step finale “end”.
IncludeFile consente di allegare un file di dati al nostro flow, Parameter è ovviamente un parametro che possiamo specificare in fase di esecuzione.
Abbiamo quindi realizzato un esempio molto semplice, per introdurre alcuni concetti di Metaflow. Proviamo ed eseguirlo:
python src/ProphetSimpleFlow.py run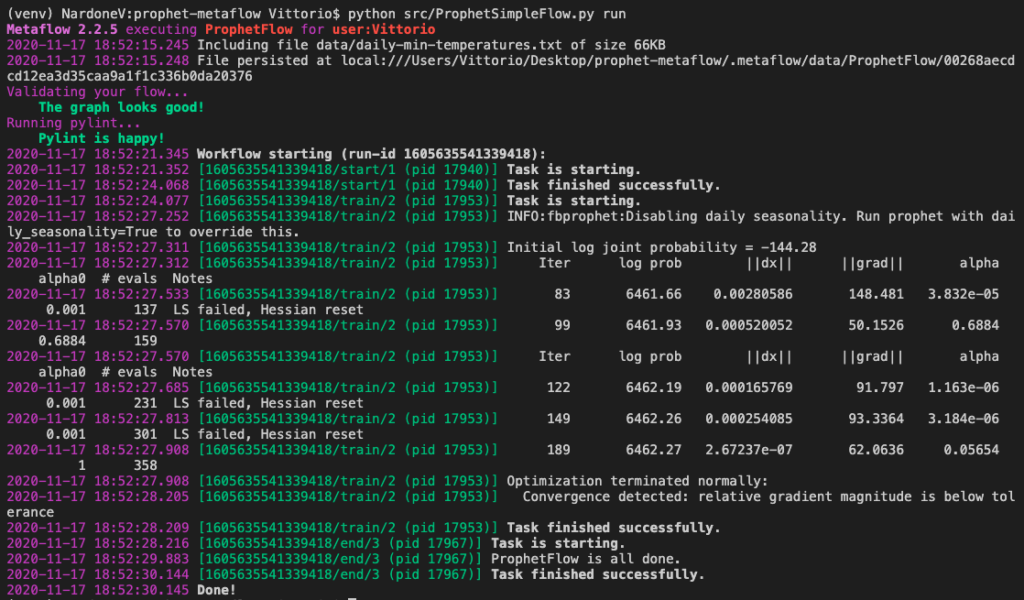
Come si vede, ad ogni esecuzione Metaflow si occupa di validare gli step del nostro flusso e il relativo codice sorgente. Tutti gli step (o task) sono eseguiti in sequenza. Un aspetto interessante di Metaflow è inoltre la possibilità di riprendere l’esecuzione di un flusso da uno step specifico, ad esempio in caso di errore.
Al termine dell’esecuzione, Metaflow memorizza automaticamente tutti gli artefatti (self.*), quindi anche il modello Prophet di cui abbiamo appena terminato il training (self.m). Vediamo come utilizzarlo in un Notebook.
Utilizzare il client Metaflow in un Notebook
Ora che il modello Prophet è stato creato, possiamo utilizzare un notebook per accedere ai risultati del flow ed effettuare delle previsioni. Utilizziamo i metodi del client Metaflow.
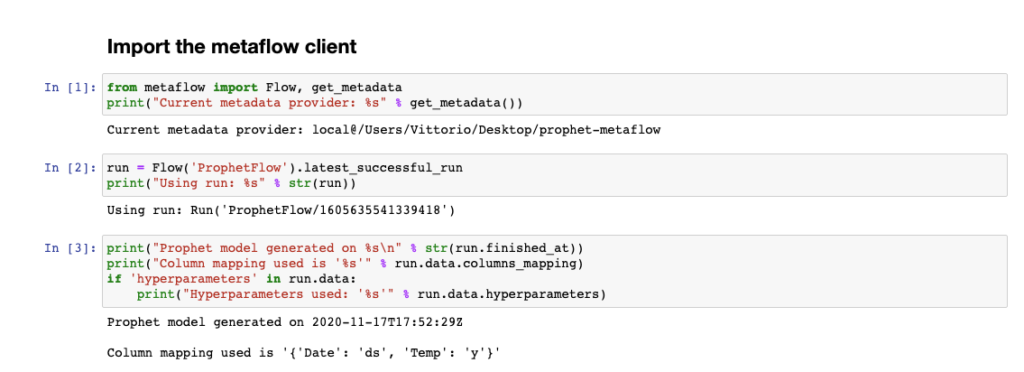
Come si può vedere, per ciascun flow è possibile consultare tutte le esecuzioni e accedere ai relativi artefatti. Il nostro modello Prophet è quindi accessibile come run.data.m. Proviamo ad utilizzarlo.
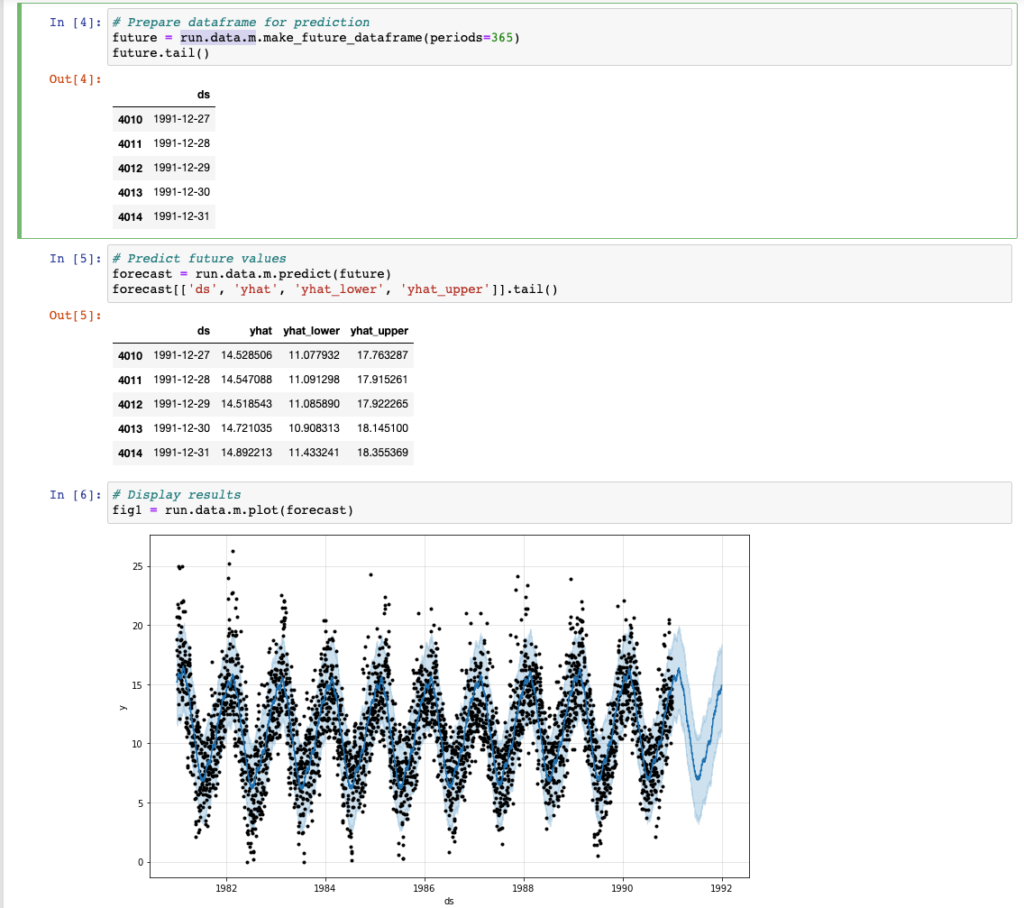
Analogamente a quanto visto in precedenza, siamo ora in grado di prevedere l’andamento della nostra time serie. Con l’introduzione di Metaflow abbiamo versionato gli artefatti (i modelli Prophet) e siamo in grado di accedere ai metadati relativi a ciascuna esecuzione del processo di training precedentemente effettuata.
Tuning degli iperparametri
Proviamo a migliorare le prestazioni del nostro modello previsionale, agendo su alcuni degli iperparametri che Prophet ci mette a disposizione. Consideriamo i seguenti:
- changepoint_prior_scale – un parametro che determina la flessibilità del trend, in particolare in occasione dei changepoint
- seasonality_prior_scale – un parametro che determina la flessibilità delle componenti stagionali
Proviamo a combinare diversi valori per questi parametri e confrontiamo le performance dei modelli ottenuti. Prophet ci mette a disposizione un comodo metodo di cross_validation per valutare le performance del modello su diversi orizzonti temporali e un metodo performance_metrics per calcolare alcune statistiche molto utili, quali ad esempio MSE e RMSE.
Utilizzeremo tali statistiche per individuare i valori di iperparametri ottimali. In questa sezione della documentazione di Prophet è approfondito l’argomento in modo esaustivo.
Come modifichiamo il nostro flow? La valutazione della performance dei modelli con differenti iperparametri è ovviamente un’attività che può essere eseguita in parallelo. Andremo quindi a creare tanti step “figli” quante sono le combinazioni dei vari valori degli iperparametri che vogliamo testare. Uno step di join al termine, raccoglierà le metriche di performance e si occuperà di individuare la migliore. Aggiungiamo quindi al nostro flow due step:
- hyper_tuning – è lo step padre, che determina tutte le combinazioni di iperparametri possibili e per ciascuna di queste esegue lo step successivo (in parallelo)
- cross_validation – è lo step di training e valutazione delle performance di un modello con una specifica combinazione di iperparametri
Rispetto al precedente flow, differisce inoltre anche lo step train: andremo a effettuare il merge degli artefatti prodotti dagli step di cross_validation, individuando la combinazione di ipermarametri con valore di RMSE inferiore. Utilizzeremo poi tale combinazione per il training del modello “definitivo”. Ecco un estratto del flow modificato:
L’esecuzione del flow richiederà, ovviamente, molto più tempo in quanto vengono testate le varie combinazioni di iperparametri su differenti orizzonti temporali. E’ questo il momento in cui possiamo decidere di passare dall’esecuzione locale di Metaflow, alla sua configurazione cloud su AWS. Vediamo come.
Configurazione di Metaflow su AWS
Come detto in precedenza, Metaflow è inizialmente configurato per utilizzare le sole risorse locali per l’esecuzione dei flow e la memorizzazione di dati e metadati.
E’ consigliato configurare Metaflow per utilizzare i servizi cloud di AWS: è possibile infatti eseguire alcuni step o l’intero codice di un flow su AWS, utilizzando il servizio AWS Batch. Dati e metadati vengono memorizzati rispettivamente su S3 e RDS, in maniera centralizzata e condivisibile con il team.
A tale scopo la strada più semplice è creare uno stack CloudFormation con tutta l’infrastruttura necessaria. Le istruzioni (e il template di CloudFormation) sono disponibili qui. Al termine della creazione dello stack, potremo configurare Metaflow per l’utilizzo delle risorse cloud con il seguente comando.
metaflow configure awsIl team di Metaflow mette a disposizione un ambiente sandbox gratuito per i propri esperimenti: richiederne l’utilizzo a questo link. Purtroppo, per questo progetto, non sono stato in grado di utilizzare la sandbox in quanto l’ambiente non consente il download i package aggiuntivi, non disponendo di connettività in uscita.
Vogliamo quindi eseguire il nostro flow su AWS Batch? Non così in fretta. Dobbiamo considerare che stiamo utilizzando un package – Prophet – che deve essere installato in quanto non presente nell’immagine docker utilizzata di default.
Per risolvere questo problema sono possibili due strade: utilizzare l’integrazione con Conda che Metaflow mette a disposizione oppure utilizzare un’immagine docker differente.
Personalmente ho preferito utilizzare questa seconda strada, in quanto mi sono scontrato con diversi problemi di compatibilità e lunghi tempi di esecuzione utilizzando Conda.
Vediamo come realizzare un’immagine docker per tale scopo.
Dopo aver effettuato la build dell’immagine e averla depositata in un repository accessibile, possiamo eseguire il nostro flow su AWS Batch con il comando seguente. L’immagine utilizzata in questo progetto è disponibile su dockerub.
python src/ProphetFlow.py run --with batch:image=vnardone/prophet-metaflowEsatto: con un semplice parametro a runtime è possibile eseguire il nostro flow interamente su AWS, utilizzando risorse di calcolo superiori rispetto al nostro laptop. La modalità di accesso agli artefatti (il modello Prophet) sarà identico anche se questi saranno ovviamente memorizzati in cloud: utilizzeremo infatti il medesimo Notebook visto in precedenza per effettuare delle previsioni senza renderci conto, di fatto, di utilizzare risorse cloud anzichè locali.
In alternativa è possibile eseguire esclusivamente gli step che richiedono più risorse computazionali su AWS Batch, utilizzando il decorator @batch. Questo andrà posto prima di ciascuno step che si intende eseguire in cloud.
@batch(image='vnardone/prophet-metaflow')
@step
def cross_validation(self):
....Personalmente preferisco quest’ultimo approccio, che consente di delegare al cloud gli step più onerosi in termini computazionali, eseguendo invece rapidamente in locale gli altri step. In questo modo è anche possibile specificare immagini docker differenti per ciascuno step, qualora sia necessario.
Conclusioni
Siamo giunti alla fine: in questo post ho parlato di un semplice progetto di ML che però abbraccia prodotti open-source molto potenti che meriterebbero ulteriori approfondimenti. Mentre Prophet è ovviamente una procedura utile per un caso specifico, la previsione di serie temporali, possiamo utilizzare Metaflow in tutti i nostri progetti di data science in quanto lo stesso framework ci aiuta a tenere “ordinato” il processo di sviluppo e deployment della soluzione.
Riassumendo quelli che penso siano i punti di forza e di debolezza di Metaflow:
Punti di forza
- Forza lo sviluppatore / data scientist a eseguire operazioni ordinate, suddivise in passaggi
- Consente di condividere automaticamente processi, dati e metadati con il team
- I processo e i dati vengono automaticamente versionati
- Il framework nasconde la complessità del backend
- Ottima integrazione con le risorse cloud AWS
Da migliorare
- L’integrazione con Conda è decisamente troppo lenta
- Le risorse AWS richieste potrebbero dimostrarsi molto onerose economicamente
Metaflow è l’unico framework di questo tipo? No! Anche ZenML e Kedro sono due validissime alternative. Ti consiglio questo ottimo articolo che mette a confronto i tre framework.
L’intero codice sorgente del progetto è disponibile in questo repository git.
Ci siamo divertiti? Alla prossima!