
Chromium and Selenium in AWS Lambda
Let’s see how it is possible to use Chromium and Selenium in an AWS Lambda function; first, some information for those unfamiliar with these two projects.
2020.09 update
Please check project repository for a new version of this project.
Chromium ver. 86.0.4240.0 and Selenium ver. 3.14.
Chromium is the open source browser from which Google Chrome derives. Browsers share most of the code and functionality. However, they differ in terms of license and Chromium does not support Flash, does not have an automatic update system and does not collect usage and crash statistics. We will see that these differences do not affect the potential of the project in the least and that, thanks to Chromium, we can perform many interesting tasks within our Lambda functions.
Selenium is a well-known framework dedicated to testing web applications. We are particularly interested in Selenium WebDriver, a tool that allows to control all the main browsers available today, including Chrome/Chromium.
Why use Chrome in a Lambda function?
What is the purpose of using a browser in an environment (AWS Lambda) that does not have a GUI? In reality there are several. Operating a browser allows you to automate a series of tasks. It is possible, for example, to test your web application automatically by creating a CI pipeline. Or, not least, web scraping.
The web scraping is a technique that allows to extract data from a website and its possible applications are infinite: monitor product prices, check the availability of a service, build databases by acquiring records from multiple open sources.
In this post we will see how to use Chromium and Selenium in a Lambda function Python to render an URL.
Example lambda function
The Lambda Function we are going to create has a specific purpose: given a URL, Chromium is used to render the related web page and a screenshot of the content is captured in PNG format. We are going to save the image in an S3 bucket. By running the function periodically, we will be able to “historicize” the changes of any site, for example the homepage of an online information newspaper.
Obviously our Lambda has many possibilities for improvement: the aim is to show the potential of this approach.
Let’s start with the required Python packages (requirements.txt).
selenium==2.53.0
chromedriver-binary==2.37.0Packages are not normally available in the AWS Lambda Python environment: we need to create a zipfile to distribute our function including all dependencies.
We get Chromium, in its Headless version, that is able to run in server environments. We need the relevant Selenium driver. Here are the links I used.
How to use Selenium Webdriver
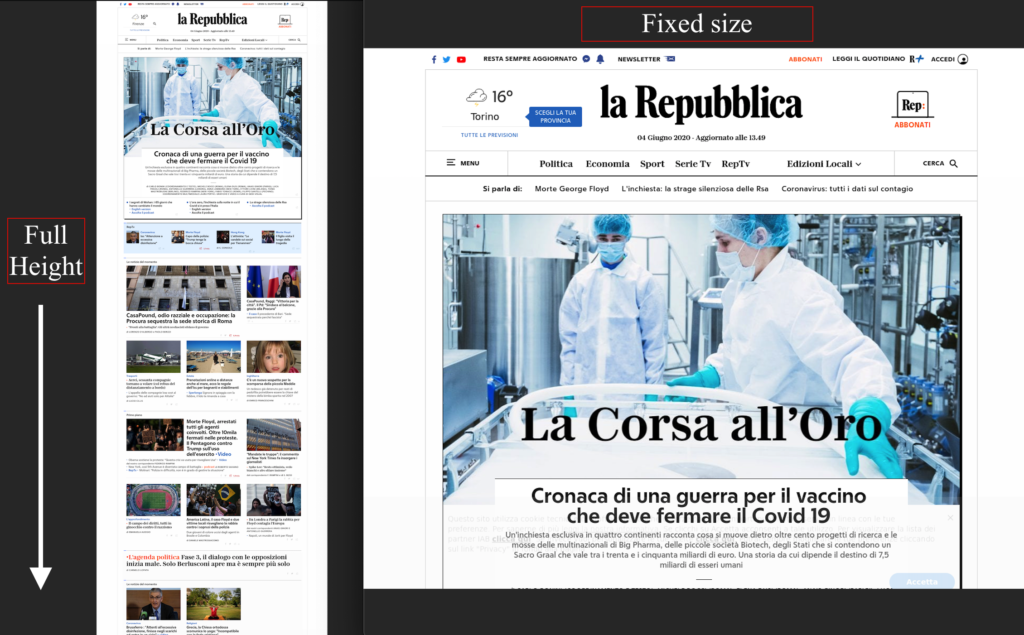
A simple example of how to use Selenium in Python: the get method allows to direct the browser to the indicated URL, while the save_screenshot method allows to save a PNG image of the content. The image will have the size of the Chromium window, which is set using the window-size argument to 1280×1024 pixels.
I decided to create a wrapper class to render a page in all its height . We need to calculate the size of the window required to contain all the elements. We use a trick, a script that we will execute after page loading. Again Webdriver exposes an execute_script method that is right for us.
The solution is not very elegant but functional: the requested URL must be loaded twice. First time browser window is set to a fixed size. After page loading, a JS script is used to determine the size of the required window. After that, original browser window is closed and a new one, correctly sized, is opened to get the full height screenshot. The JS script used was taken from this interesting post .
Wrapper is also “Lambda ready”: it correctly manages the temporary paths and the position of the headless-chromium executable specifying the necessary chrome_options.
Let’s see what our Lambda function is like:
The event handler of the function simply takes care of instantiating our WedDriverScreenshot object and uses it to generate two screenshots: the first with a fixed window size (1280×1024 pixels). For the second, the Height parameter is omitted, which will be automatically determined by our wrapper.
Here are the two resulting images, compared with each other, relating to the site www.repubblica.it
Deployment of the function
I collected in this GitHub repository all files needed to deploy the project on AWS Cloud. In addition to the files already analyzed previously, there is a CloudFormation template for stack deployment. The most important section obviously concerns the definition of the ScreenshotFunction : some environment variables such as PATH and PYTHONPATH are fundamental for the correct execution of the function and Chromium. It is also required to pay attention to the memory requirements and the timeout setting: loading a page can take several seconds. The lib path includes some libraries required for the execution of Chromium and not present by default in the Lambda environment.
As usual I prefer to use a Makefile for the execution of the main operations.
## download chromedriver, headless-chrome to `./bin/`
make fetch-dependencies
## prepares build.zip archive for AWS Lambda deploy
make lambda-build
## create CloudFormation stack with lambda function and role.
make BUCKET=your_bucket_name create-stack The CloudFormation template requires an S3 bucket to be used as a source for the Lambda function deployment. Subsequently the same bucket will be used to store the PNG screenshots.
Conclusions
We used Selenium and Chromium to render a web page. It is a possible application of these two projects in the serverless field. As anticipated, another very interesting application is web scraping. In this case, Webdriver’s page_source attribute allows access to the sources of the page and a package such as BeautifulSoup can be very useful for extracting the data we intend to collect. The Selenium package for Python offers several methods to automate other operations: please check the excellent documentation.
We will see an example of web scraping in one of the next blog posts! At the moment, have a look of this post GitHub repository.
Did we have fun? See you next time!
19 Comments
Leave a Comment
You must be logged in to post a comment.
Hello Vittorio Nardone!
Thank-you very much for a great professional high standard example of using Selenium to download files to S3!
Your example gives the full path of the files that need to be saved using the lambda “/tmp” directory. The problem I have is setting the Chrome download location. The URL I am accessing has a submit button that will download a file when it is clicked. On my own PC I have code working where it will get downloaded to the windows download directory. For the lambda function I added the lines below, and then searched the “7tmp” directory and all of its sub-directories, but could not find the file that was suppose to be downloaded:
folder = ‘/tmp’
prefs = {“download.default_directory”: folder}
chrome_options.add_experimental_option(“prefs”, prefs)
driver = webdriver.Chrome(chrome_options=chrome_options)
Do you have any suggestions on how I can direct Chrome where to download the file? Or what I might be doing wrong?
Hello Bill!
I think you should try something like this:
path_dest = ‘//path/to/download/’
prefs = {}
prefs[‘profile.default_content_settings.popups’]=0
prefs[‘download.default_directory’]=path_dest
chrome_options.add_experimental_option(‘prefs’, prefs)
driver = webdriver.Chrome(chrome_options=chrome_options)
I found this hint here
Hope it helps.
Hi Vittorio,
Thanks for your answer. The problem was the versions of Chrome before 58 did not allow downloading files. Here is more info:
https://bugs.chromium.org/p/chromium/issues/detail?id=696481
I have been doing a lot of battling to find the right version that is small enough to upload to AWS Lambda. I will give you another update when I find that.
Bill Worthington
Thanks again for the very professionally done project that helped me get a great start on this!
Are you able to get headless working with latest chrome driver. I see a few issues with Chrome 2.37 and it is more than a year old.
Hi Aly,
I’ve updated project to use:
– Chromium 69.0.3497.81 (severless-chrome 1.0.0-55)
– Chromedriver 2.43
– Selenium 3.14
This is last release of severless-chrome project. I need to try a new solution in order to use last Chromium version in AWS Lambda.
Hope it helps.
Hi Vittorio,
I got this error using your code exactly.
do you know why?
{
“errorMessage”: “module ‘selenium.webdriver’ has no attribute ‘ChromeOptions'”,
“errorType”: “AttributeError”,
“stackTrace”: [
” File \”/var/task/src/lambda_function.py\”, line 20, in lambda_handler\n driver.save_screenshot(os.environ[‘URL’], ‘/tmp/{}-fixed.png’.format(screenshot_file), height=1024)\n”,
” File \”/var/task/src/webdriver_screenshot.py\”, line 58, in save_screenshot\n chrome_options=self.__get_default_chrome_options()\n”,
” File \”/var/task/src/webdriver_screenshot.py\”, line 24, in __get_default_chrome_options\n chrome_options = webdriver.ChromeOptions()\n”
]
}
Hi! I’m not able to replicate it.
Tested today on a fresh AWS CloudFormation stack and it works.
Hi, I use your solution, this runs perfectly in local env if I comment the line
chrome_options.binary_location = os.getcwd() + “/bin/headless-chromium”
But when I tried to run this in AWS Lambda I got the next error
“Message: unknown error: Chrome failed to start: exited abnormally\n (chrome not reachable)\n (The process started from chrome location /var/task/bin/headless-chromium is no longer running, so ChromeDriver is assuming that Chrome has crashed.)\n (Driver info: chromedriver=2.43.600233 (523efee95e3d68b8719b3a1c83051aa63aa6b10d),platform=Linux 4.14.177-104.253.amzn2.x86_64 x86_64)\n”
Any suggestion?
Greats
Hi!
Please check project repository.
I’ve updated project to successfully use:
Hi Vittorio,
Thanks for this awesome project! However, I am getting this error while trying to run it offline:
Message: unknown error: Chrome failed to start: exited abnormally
(chrome not reachable)
(The process started from chrome location /var/task/bin/headless-chromium is no longer running, so ChromeDriver is assuming that Chrome has crashed.)
(Driver info: chromedriver=2.43.600233 (523efee95e3d68b8719b3a1c83051aa63aa6b10d),platform=Linux 5.4.0-47-generic x86_64)
I did see it is a common error people face :
https://stackoverflow.com/questions/60081937/webdriverexception-message-unknown-error-chrome-failed-to-start-crashed-erro
Have you ever faced this problem or do you have any suggestions?
Thanks
Barun
Hi Barun,
how did you try to run it offline?
I think the only way to run it offline is using Docker.
Please check my project github repository
Fast steps:
I’ve updated project to successfully use:
Hope it helps. Bye and thanks 🙂
Hi’ I’ve implemented my first AWS lambda project.
is there any begginers manual for the required setps to run the function manully ?
th zip was upluaded to the se bucket and I see the stack was created.
Hi Doron,
I suggest to google for “aws lambda 101” to find tutorial about AWS Lambda.
Best,
Vittorio
Hi Vittorio,
Was I right that I moved the chromedriver into the /tmp folder so that the chromedriver can be executed? It didn’t work when I deployed it as a layer.
Btw, I am getting an error:
Message: unknown error: Chrome failed to start: exited abnormally.
(chrome not reachable)
Can you share the direct download links of the binaries that u used?
Thanks
Hi!
No, I think it’s not required to move chromedriver in /tmp folder.
What was not working when you deployed it as a layer?
Chrome binary is from this awesome project: https://www.npmjs.com/package/chrome-aws-lambda
Hi Vittorio,
What should we set Environment variables in aws lambda? Thanks.
Hi!
In my code, environment variables are set by Cloudformation template.
This is a short extract:
PYTHONPATH: "/var/task/src:/opt/python"PATH: "/opt/bin:/opt/bin/lib"
URL: Ref: WebSite
BUCKET: Ref: BucketName
DESTPATH: Ref: ScreenshotsFolder
Hi Vittorio!
I do everything as you suggested and I am getting below error when I try to test the code on AWS Lambda:
”
START RequestId: 202bab58-b18c-49e0-b743-45a206423bd6 Version: $LATEST
Unable to import module ‘lambda_function’: No module named ‘boto3’
”
I am waiting for your helps. Thanks.
Hi!
In my sample source code, module boto3 is installed in lambda layer. It seems you are not using it.
Please try in this order:
make lambda-layer-buildmake lambda-function-build
make BUCKET=your_bucket_name create-stack
Cloudformation stack provides lambda and lambda layer resources creation.